Particularly in the area of generative models, Generative Adversarial Networks, or GANs, have completely transformed artificial intelligence. Since its introduction by Ian Goodfellow and associates in 2014, GAN has created new opportunities for producing realistic data in a variety of fields. The foundations of GANs, their architecture, uses, and possible future approaches will all be covered in this blog.
We will learn:
- What is a Generative Adversarial Network (GANs)?
- Types of GANs
- Architecture of GANs
- How does a GAN work?
- Application Of Generative Adversarial Networks (GANs)
- Advantages of GAN
- Disadvantages of GAN
- Conclusion
- FAQs
What is a Generative Adversarial Network (GAN)?
For unsupervised learning, Generative Adversarial Networks (GANs) are a potent class of neural networks. To produce realistic artificial data, they are made up of two primary parts: the discriminator and the generator, which operate against one another.
- Generator: Using random noise, this network creates fresh data samples. Its objective is to generate data that is identical to actual data.
- Discriminator: To discern between data produced by the generator and actual data, this network analyzes data samples. It seeks to precisely determine if a sample is real or synthetic.
The steps involved in the GAN process are as follows:
- Generative: A generative model, which explains how data is produced in terms of a probabilistic model, is learned by the generator. To do this, samples that closely resemble the distribution of actual data must be created.
- Adversarial: The word “adversarial” describes the training process’ competitive aspect. A game is played in which the discriminator and generator compete with one another. The generator attempts to deceive the discriminator, while the discriminator attempts to discern between authentic and fraudulent data.
- Networks: Deep neural networks, which are strong AI training algorithms, are used by GANs. The discriminator and generator can discover intricate patterns and representations in the data thanks to these networks.
Both the discriminator and the generator get better over time as a result of this adversarial process. The discriminator improves its ability to identify phony data, while the generator improves its ability to produce realistic data. In order to reach a balance where the discriminator is duped roughly half the time, this competition keeps going until the generator generates samples that the discriminator cannot consistently tell apart from actual data.
Image synthesis, style transfer, and text-to-image synthesis are just a few of the many uses for GANs, which have completely transformed generative modeling. They have shown themselves to be extremely adaptable artificial intelligence tools, generating realistic, high-quality samples in a variety of fields.
Types of GAN
The following is a basic explanation of the many Generative Adversarial Network (GAN) types:
- Vanilla GAN: The most basic type of GAN is called a vanilla GAN. It contains a discriminator that attempts to determine whether the data is authentic or fraudulent, as well as a generator that generates data. Simple neural networks serve as both the discriminator and the generator. Enhancing the generator to produce realistic data is the aim.
- Conditional GAN (CGAN): Both the discriminator and the generator receive additional information in this type. For instance, you can specify a label (such as “cat” or “dog”) to direct the production process if you like to produce photos of a certain kind of object. This aids in producing data that corresponds to particular circumstances.
- Deep Convolutional GAN (DCGAN): Convolutional neural networks (ConvNets) are used in place of simple neural networks in Deep Convolutional GANs (DCGANs). ConvNets do well in image processing. Because DCGANs learn from the patterns in the data to produce high-quality images, they are widely used.
- Laplacian Pyramid GAN (LAPGAN): LAPGAN creates images in phases using a unique method known as a Laplacian pyramid. A low-resolution image is first produced, and then more detail is added progressively. This method aids in producing incredibly detailed and excellent photos.
- Super Resolution GAN (SRGAN): SRGAN improves the appearance of low-resolution images. A deep neural network is used to add information to a hazy image, making it sharper and more readable. This is helpful for enhancing image quality.
Architecture of GAN
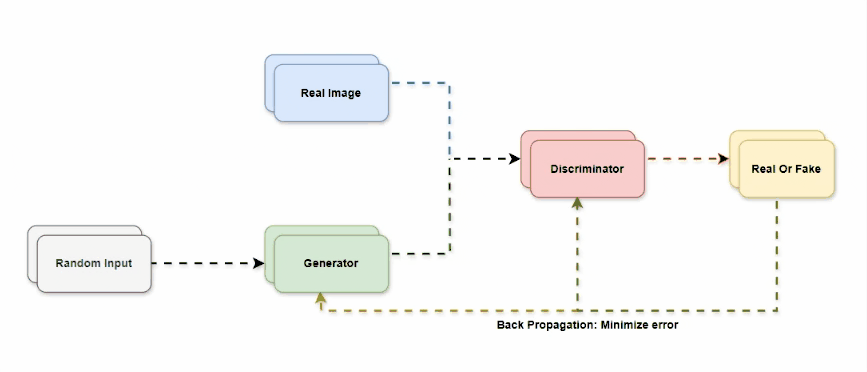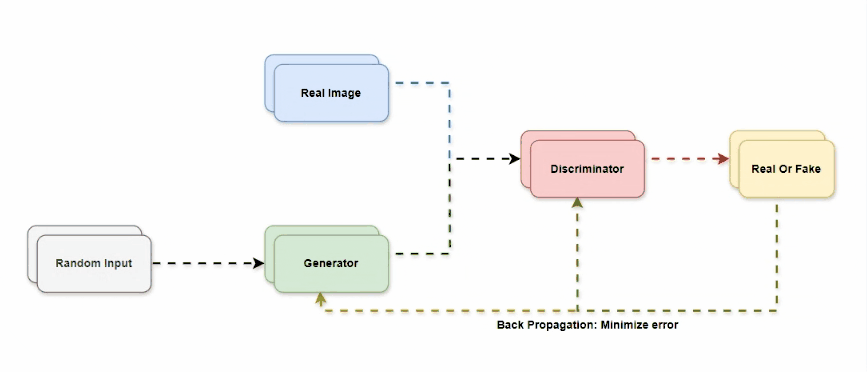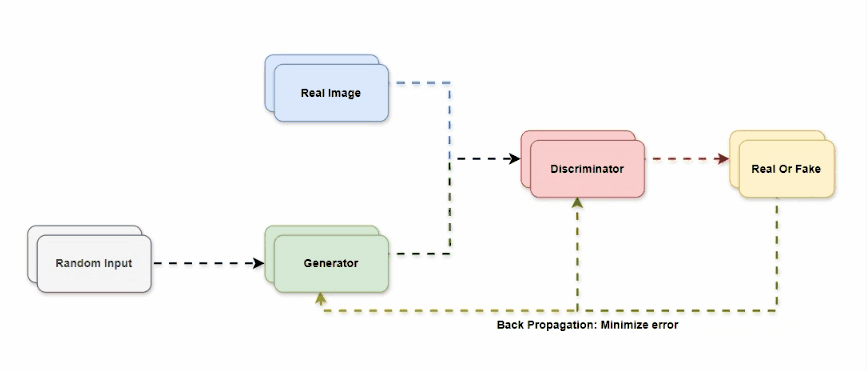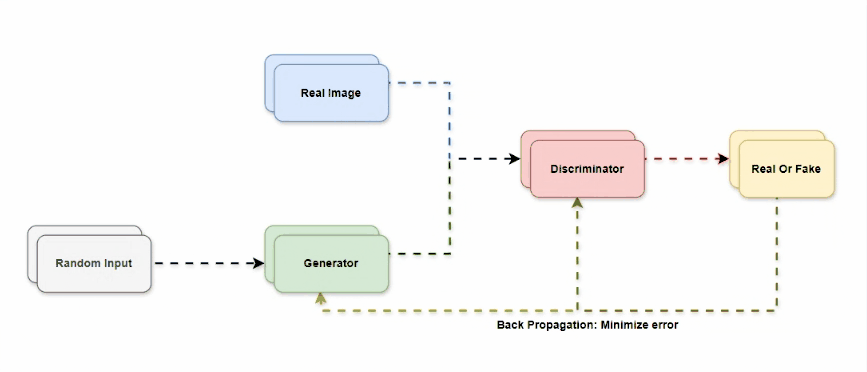
The graphic provides a straightforward explanation of the architecture of a Generative Adversarial Network (GAN), emphasizing the interplay between the Generator and the Discriminator, the network’s two primary components. Here is a detailed breakdown of the architecture:
1. Random Input
- Input: Often called a noise vector or latent vector, the process starts with a random input. Usually, this input is taken from a straightforward distribution, like a uniform or Gaussian distribution.
- Purpose: The generator can provide a wide range of outputs thanks to the randomness.
2. Generator
- Function: To create a synthetic image, the generator uses a sequence of transformations (sometimes represented as layers of a neural network) on the random input.
- Objective: The generator’s objective is to produce realistic-looking visuals that can deceive the discriminator into believing they are authentic.
3. Real Image
- Comparison Data: The system receives real photos from the training dataset in addition to the synthetic images produced by the generator.
- Purpose: The discriminator is trained to differentiate between actual and fake images using these real photos.
4. Discriminator
- Function: Both the synthetic images produced by the generator and actual photos are sent to the discriminator. After undergoing a number of changes (neural network layers), it produces a probability score that indicates whether the input image is authentic or not.
- Objective: The discriminator’s objective is to correctly identify actual images as such and manufactured ones as fake .
5. Real or Fake
- Output: After processing a picture, the discriminator outputs a conclusion indicating whether it thinks the image is real or fake.
6. Backpropagation
- Error Minimization: Calculations are made based on the discriminator’s choices. To reduce these faults, backpropagation is then used to update the discriminator and generator.
- Generator’s Loss: The generator seeks to reduce the discriminator’s capacity to discern between authentic and fraudulent images. It accomplishes this by producing pictures that the discriminator deems authentic.
- Discriminator’s Loss: The discriminator wants to be as accurate as possible at differentiating between authentic and fraudulent photos.
7. Training Loop
- Iterative Process: In this training approach, the discriminator and generator are trained concurrently using an iterative loop. The discriminator gets better at spotting fakes, and the generator gets better at producing realistic images.
- Generator Update: To increase the likelihood that the discriminator would classify the images as real, the generator is changed.
- Discriminator Update: The discriminator can now more accurately discern between authentic and fraudulent photos.
How are multilayer perceptrons used in the framework for training the models?
Multilayer perceptrons (MLPs) are used in model training by processing inputs through multiple layers of neurons, with each layer learning hierarchical features. During training, backpropagation adjusts weights to minimize error, enabling the network to learn complex patterns from data.
How does a GAN work?
The following steps describe how GAN operates:
- Initialization:
- Start by building two neural networks: a discriminator (D) and a generator (G).
- G’s assignment is to produce fresh data that mimics authentic data.
- D’s assignment is to distinguish between bogus data (created by G) and true data (from a training batch).
- Generator’s First Move:
- A random noise vector (random values) is what G begins with.
- G creates a new data sample (like a picture) from this noise.
- Discriminator’s Turn:
- D is given two different kinds of inputs:
- Actual samples of the training set’s data.
- G-generated fake data samples.
- D’s task is to ascertain the authenticity of each input and produce a likelihood score:
- If the data is authentic, it will be about 1.
- If the data is fraudulent, it is near zero.
- D is given two different kinds of inputs:
- The Learning Process:
- If D accurately states: Real data is real (score near 1).
- phony data is considered to be phony (scoring near 0).
- G and D both receive a small incentive.
- The idea is for G to finally fool D because it won’t learn much if D is always right.
- When D incorrectly classifies G’s fictitious data as authentic (score near 1), G receives a large reward, enhancing its capacity to produce realistic data.
- If D accurately states: Real data is real (score near 1).
- Generator’s Improvement:
- When D mistakenly labels G’s fake data as real (score close to 1):
- G is rewarded significantly, improving its ability to create realistic data.
- D is penalized for being fooled.
- When D mistakenly labels G’s fake data as real (score close to 1):
- Discriminator’s Adaptation:
- When D correctly identifies fake data (score close to 0):
- G is not rewarded when D accurately detects bogus data (score near 0)
- D becomes more adept at identifying bogus data.
- When D correctly identifies fake data (score close to 0):
- Ongoing Duel:
- By pushing one another, G and D keep getting better.
- As G becomes more adept at producing realistic data, D finds it more difficult to distinguish between the two.
- When G is well-trained, it should eventually become so good that D is unable to consistently tell the difference between actual and phony data.
What is the proposed framework for estimating generative models introduced in this paper?
The proposed framework for estimating generative models in the paper leverages a variational approach, incorporating both likelihood and divergence measures to optimize model parameters. It aims to balance complexity and accuracy, improving generative model performance in real-world applications.
What is the unique solution mentioned in the context of functions G and D?
The unique solution refers to the specific values or behavior of functions G and D that satisfy a given set of conditions, ensuring consistency and correctness in their outputs. This uniqueness guarantees that the solution is well-defined and reliable.
Is there a need for Markov chains or unrolled approximate inference networks during training or sample generation?
Markov chains and unrolled approximate inference networks are useful during training and sample generation for certain models, especially in generative tasks. They help approximate complex distributions and improve convergence by simplifying inference, but aren’t always necessary for every model type.
Application Of Generative Adversarial Network (GAN)
Generative Adversarial Networks (GANs) are extremely adaptable and have numerous uses in a variety of domains. Here are a few typical applications for GANs:
- Image Synthesis and Generation: By learning from a dataset of preexisting images, GANs are able to produce new, realistic images. This feature is helpful for creating realistic avatars, sharp images, and original artwork.
- Image-to-Image Translation: GANs are capable of converting images between styles while maintaining crucial details. For instance, they can apply various artistic styles to photographs, transform sketches into realistic images, or alter a scene from day to night.
- Text-to-Image Synthesis: Using text descriptions as input, GANs may produce images. GANs can produce an image that corresponds to a sentence or caption. This is helpful for turning text-based instructions into visual content.
- Data Augmentation: To improve already-existing datasets, GANs can produce synthetic data samples. By offering more varied training data, this enhances the generalizability and resilience of machine learning models.
- Data Generation for Training: GANs are able to enhance low-resolution photos’ quality and resolution. GANs are capable of producing high-quality images from lower-quality inputs by learning from pairs of low-resolution and high-resolution photos. This is useful in areas such as satellite imaging, medical imaging, and video enhancement.
Advantages of GAN
Generative Adversarial Networks (GANs) have the following benefits:
- Synthetic Data Generation: GANs are capable of producing fresh, synthetic data that closely resembles actual data. This offers more data for machine learning model testing and training, which is helpful for creative applications, anomaly detection, and data augmentation.
- High-Quality Results: GANs may generate excellent, photorealistic outcomes in a number of domains, including as music production, video synthesis, and picture synthesis. Realistic and intricate material can be produced.
- Unsupervised Learning: Labeled data is not necessary for GANs to learn. They are therefore perfect for unsupervised learning jobs where it is difficult or costly to collect labeled data.
- Versatility: GANs are extremely adaptable and can be applied to a variety of applications,
- Image Synthesis: Making fresh images that look like the training data is known as image synthesis.
- Text-to-Image Synthesis: Creating visuals from word descriptions is known as text-to-image synthesis.
- Image-to-Image Translation: Transforming images from one style to another is known as image-to-image translation.
- Anomaly Detection: Finding anomalous patterns or data points is known as anomaly detection.
- Data Augmentation: Adding more artificial samples to datasets to improve them is known as data augmentation.
Disadvantages of GAN
Generative Adversarial Networks (GANs) have the following drawbacks:
- Training Instability: Training GANs can be difficult. They frequently experience failure to converge to a solution, mode collapse (when the generator produces a limited choice of outputs), or instability.
- Computational Cost: GAN training can be time-consuming and resource-intensive, particularly for large datasets or high-resolution pictures. They need a lot of processing power, which can be expensive.
- Overfitting: GANs have the tendency to overfit training data, producing artificial data that lacks diversity and is too close to the actual training data.
- Bias and Fairness: GANs have the ability to pick up on and magnify biases in training data, which could result in biased or unfair synthetic data that reflects and reinforces preconceived notions.
- Interpretability and Accountability: GANs are frequently referred to as “black boxes,” which denotes that it is challenging to comprehend or elucidate how they operate internally. It may be challenging to guarantee accountability, openness, and equity in their applications because to this lack of interpretability.
What do the experiments demonstrate about the potential of the proposed framework?
The experiments highlight the proposed framework’s potential to significantly improve performance, demonstrating its effectiveness in solving complex problems. It shows promising results in terms of efficiency, scalability, and accuracy, positioning it as a viable solution for real-world applications.
What are some of the code, data, and media resources linked to this paper?
To assist you better, could you please provide the title or some context about the paper you’re referring to? That way, I can help you accurately summarize the resources related to it for your blog.
What demos are available related to the content of this paper?
For demos related to the content of this paper, you can explore interactive simulations, code repositories, or platforms like GitHub, where practical implementations are often shared. These demos allow for hands-on experience with the concepts discussed in the paper.
What is the significance of the listed references and citations for this paper?
The references and citations in a paper highlight the sources of key ideas, methodologies, and data that support the research. They provide credibility, acknowledge prior work, and help readers trace the academic foundation of the paper’s claims.
Conclusion
Without a question, Generative Adversarial Networks have expanded the realm of artificial intelligence. GANs remain at the vanguard of AI innovation, producing everything from beautiful visual art to improving data for machine learning models. We may anticipate even more ground-breaking uses and advancements in GAN technology as research continues.
FAQs
What is the main objective of a GAN?
The main objective of a Generative Adversarial Network (GAN) is to generate new, realistic data that resembles a given dataset by having two neural networks—the generator and the discriminator—compete against each other. This setup enables GANs to produce highly realistic images, text, and other data types, making them valuable for tasks like image synthesis, data augmentation, and creative content generation.
What is mode collapse in GANs?
Mode collapse in Generative Adversarial Networks (GANs) occurs when the generator starts producing a limited variety of outputs, often repeating similar samples, instead of capturing the full diversity of the training data. This problem reduces the quality of the generated data, as the model fails to represent all possible patterns or modes in the dataset, making it a significant challenge in training GANs effectively.
What is a Conditional GAN (cGAN)?
A Conditional GAN (cGAN) is a type of Generative Adversarial Network where both the generator and discriminator receive additional information (conditions) as input, such as class labels or specific attributes. This conditioning allows cGANs to generate targeted outputs, like images of a specific category, making them powerful for tasks like image synthesis, style transfer, and data augmentation in controlled scenarios.
How are GANs evaluated?
Generative Adversarial Networks (GANs) are evaluated using a combination of qualitative and quantitative methods. Common metrics include Inception Score (IS) and Fréchet Inception Distance (FID), which measure the quality and diversity of generated images by comparing them to real data distributions. Additionally, human evaluation and visual inspection are often used to assess the realism of outputs, as GANs aim to produce outputs indistinguishable from real examples.
How is a GAN implemented?
A Generative Adversarial Network (GAN) is implemented using two neural networks: a generator and a discriminator. The generator creates synthetic data, while the discriminator evaluates its authenticity. During training, the generator tries to produce realistic data to fool the discriminator, while the discriminator learns to differentiate between real and fake data. This adversarial process continues until the generator produces data that closely resembles real samples, achieving a balance where both networks are optimally trained.
Related/References
- Visit our YouTube channel “K21Academy”
- Join Our Generative AI Whatsapp Community
- What is Generative AI & How It Works?
- What is Prompt Engineering?
- 𝐖𝐡𝐚𝐭 𝐢𝐬 𝐚 𝐥𝐚𝐫𝐠𝐞 𝐥𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐦𝐨𝐝𝐞𝐥 (𝐋𝐋𝐌)?
- 𝐖𝐡𝐚𝐭 𝐈𝐬 𝐍𝐋𝐏 (𝐍𝐚𝐭𝐮𝐫𝐚𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠)?
- Generative AI for Kubernetes: K8sGPT
Next Task: Enhance Your Azure AI/ML Skills

